

it’s very easy to understand how does Elasticsearch scoring works.
Lucene/Elasticsearch uses the Boolean model to find matching documents, and a formula called the practical scoring function to calculate the score.
Boolean model ————> Practical scoring function
Here is my post on the basics of Elasticsearch.
STEP – 1:
The bool query implements the Boolean model and, in this example, will include only documents that contain either of the query terms.
Example: Let’s say we have a total of 100 documents, out of which 20 documents have either of the query terms.
STEP – 2:
(this step runs for every boolean model passed documents. In our case, this step runs for the above 20 documents.)
First, a document matches a query.
Second, Lucene calculates its score for that query, combining the score of each matching term.
Elasticsearch uses Practical scoring function for scoring.
STEP – 3:
Run for each query document pair

- score(q, d):
Relevance score of document d for query q. The score is the product of queryNorm(q), coord(q, d) and summation of product of (tf(t in d), idf(t)^2, t.getboost(), norm(t,d) ) for each term in query.
2. queryNorm(q) is the query normalization factor
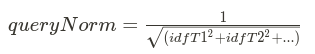
where T1, T2,… are terms in the query.
![]() is the sum of squares of Inverse-document-frequencies of the terms.
is the sum of squares of Inverse-document-frequencies of the terms.
The same query normalization factor is applied to every document, as it depends on the terms of the query only.
The query normalization factor is an attempt to normalize a query. As a result, one query can be compared with the results of another.
At the beginning of the query, queryNorm is calculated.
3. coord(q,d) is the coordination factor.
The coordination factor (coord) is used to reward documents that contain a higher percentage of the query terms.
More query terms that appear in the document, the greater the chances that the document is a good match for the query.
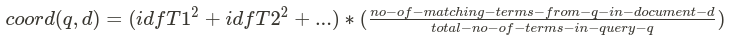
- where T1, T2,… are terms in the query.
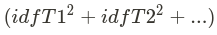 is called sum Of Squared Weights
is called sum Of Squared Weights
- example: Imagine that we have a query for
I like applesand that the weight for each term is 1.5. Without the coordination factor, the score would just be the sum of the square of the IDF of the terms in a document. Example:- Document with
apples→ score: 1.5 - Another document
like apples→ score: 3.0 - One more document with
I like apples→ score: 4.5 - The coordination factor multiplies the score by the number of matching terms in the document and divides it by the total number of terms in the query. With the coordination factor, the scores would be as follows:
- Document with
apples→ score:1.5 * 1 / 3= 0.5 - Another document with
like apples→ score:3.0 * 2 / 3= 2.0 - One more document with
I like apples→ score:4.5 * 3 / 3= 4.5 - The coordination factor results in the document that contains all three terms being much more relevant than the document that contains just two of them.
- Document with
- Run for each term in query q:- sum ( weights for each term t in the query q for document d.)
- tf(t in d) is the term frequency for term t in document d.

2. idf(t) is the inverse document frequency for term t.
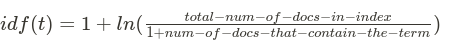
How often does the term appear in all documents in the collection?
The more often, the lower the weight.
Common terms like and or the contribute little to relevance, as they appear in most documents, while uncommon terms like elastic or hippopotamus help us zoom in on the most interesting documents.
3. t.getBoost() is the boost that has been applied to the query.
Use the boost parameter at search time. As a result, one query clause becomes more important than another.
4. norm(t,d) is the field-length norm, combined with the index-time field-level boost if any.
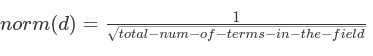
How long is the field? The shorter the field, the higher the weight.
If a term appears in a short field, such as a title field, it is more likely that the content of that field is about the term than if the same term appears in a much bigger body field.
Reference:-
https://www.elastic.co/guide/en/elasticsearch/guide/current/practical-scoring-function.html